MangoBench: A Benchmark for Multi-Agent Goal-Conditioned Offline Reinforcement Learning
Abstract
Offline Multi-Agent Reinforcement Learning (MARL) is critical for coordinating multiple agents in costly and unsafe environments, yet existing methods struggle from high sensitivity to reward functions and weak generalization to new goals, limiting its practical impact. Inspired by single-agent Offline Goal-Conditioned RL (OGCRL), we propose the first goal-conditioned offline MARL framework, extending OGCRL to multi-agent settings under both fully decentralized and centralized training with decentralized execution (CTDE) paradigms. To systematically evaluate this setting, we introduce MangoBench, the first fully cooperative multi-goal benchmark for MARL, covering 3 environments, 4 agent types, and 47 tasks, designed to assess joint-control locomotion, synchronous and asynchronous bimanual manipulation, and robustness to high-dimensional inputs. Extensive experiments demonstrate that our baselines achieve strong multi-goal generalization under sparse rewards, yet no method dominates all tasks, revealing both the intrinsic complexity and the unexplored potential of goal-conditioned offline MARL.
Overview
Why Goal-Conditioned Offline MARL?
Offline MARL learns coordinated policies purely from pre-collected datasets, avoiding costly and unsafe real-world exploration. However, two fundamental limitations hinderits practical deployment: even minor perturbations in handcrafted reward functions can cause drastic policy shifts, and task-specific reward designs prevent agents from generalizing to new goals. Goal-conditioned learning provides a natural and domain-agnostic alternative: instead of optimizing a fixed reward, agents learn to reach arbitrary target states from data. This formulation enables unsupervised multi-goal training and encourages reusable, general-purpose coordination policies.
Our Framework
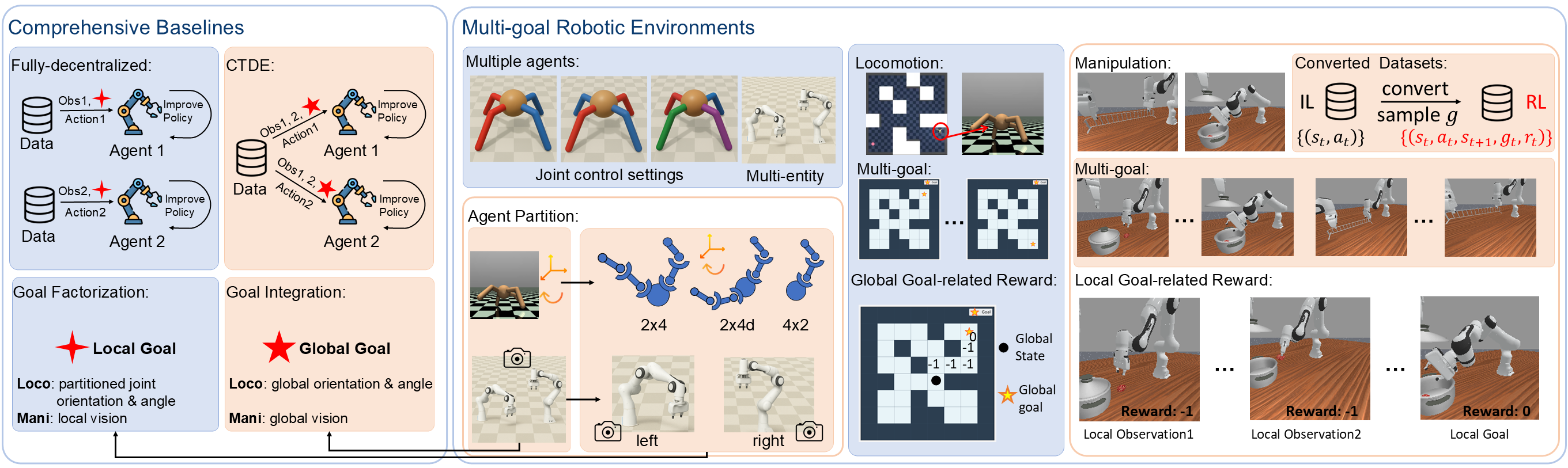
We establish the first goal-conditioned offline MARL framework, extending OGCRL to multi-agent scenarios under both fully decentralized and CTDE paradigms. In the decentralized setting, we introduce a structured factorization of the global goal into individualized representations, enabling each agent to act on local information alone. In the CTDE setting, individual goals are integrated into a unified global objective for richer value learning, while each actor remains conditioned on its local goal for decentralized execution.
MangoBench
Existing MARL benchmarks primarily evaluate online algorithms using dense, task-specific rewards, making them unsuitable for goal-conditioned offline scenarios that rely on sparse, goal-based rewards and require multi-goal generalization. Moreover, most current environments focus only on single-goal evaluations, leading to biased and incomplete assessments of goal-conditioned policies. To address these gaps, we create MangoBench — the first fully cooperative multi-goal benchmark for goal-conditioned offline MARL. It covers 3 environments, 4 agent types, 45 locomotion tasks, 2 manipulation tasks, and 6 baseline algorithms, supporting both multi-entity and joint-control configurations with sparse binary rewards.
Features
- First goal-conditioned offline MARL framework.
- Propose 6 baseline algorithms, supporting for both fully decentralized and CTDE training paradigms.
- 3 environments, 4 agent types, and 47 cooperative multi-goal tasks under different levels of difficulty.
- Goal-related rewards, standardized goal-conditioned MARL datasets, and multi-goal evaluation.
Proposed Baseline Algorithms
- GCMBC: A fully decentralized extension of GCBC, serving as a fundamental baseline representing the behavioral performance of the dataset.
- ICRL: A fully decentralized multi-agent extension of CRL, designed to evaluate the effectiveness of contrastive value learning in handling sparse rewards for multi-agent tasks.
- IHIQL and HIQL-CTDE: To build stronger benchmark baselines and evaluate different training paradigms, we extend the state-of-the-art HIQL into the goal-conditioned offline MARL setting, introducing IHIQL (fully decentralized) and HIQL-CTDE (centralized training with decentralized execution), both leveraging hierarchical policies to enhance robustness against sparse rewards and improve long-horizon reasoning.
- GCOMIGA and GCOMAR: To evaluate whether the current offline MARL can robustly handle the noise caused by sparse rewards to learn useful policy under the goal-conditioned environment, we designed GCOMIGA and GCOMAR by goal relabeling and randomly goal sampling, the goal-conditioned variants of OMIGA and OMAR.
Proposed Benchmark: MangoBench
MangoBench combines multi-agent setting, converted RL datasets, multi-goal evaluation, rewards design, and different tasks for cooperative locomotion and manipulation.
Cooperative Locomotion
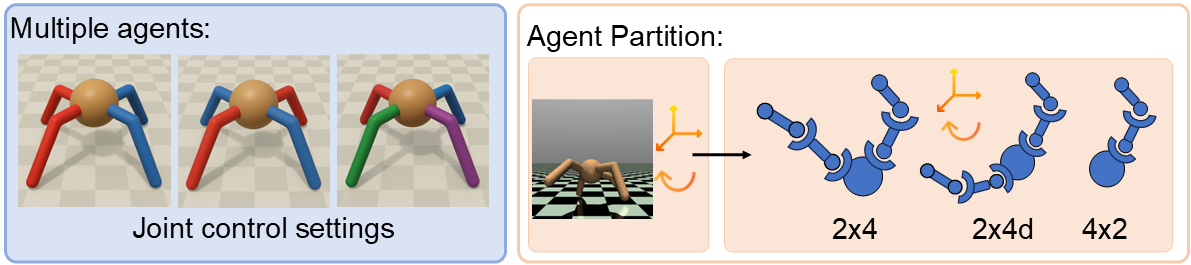
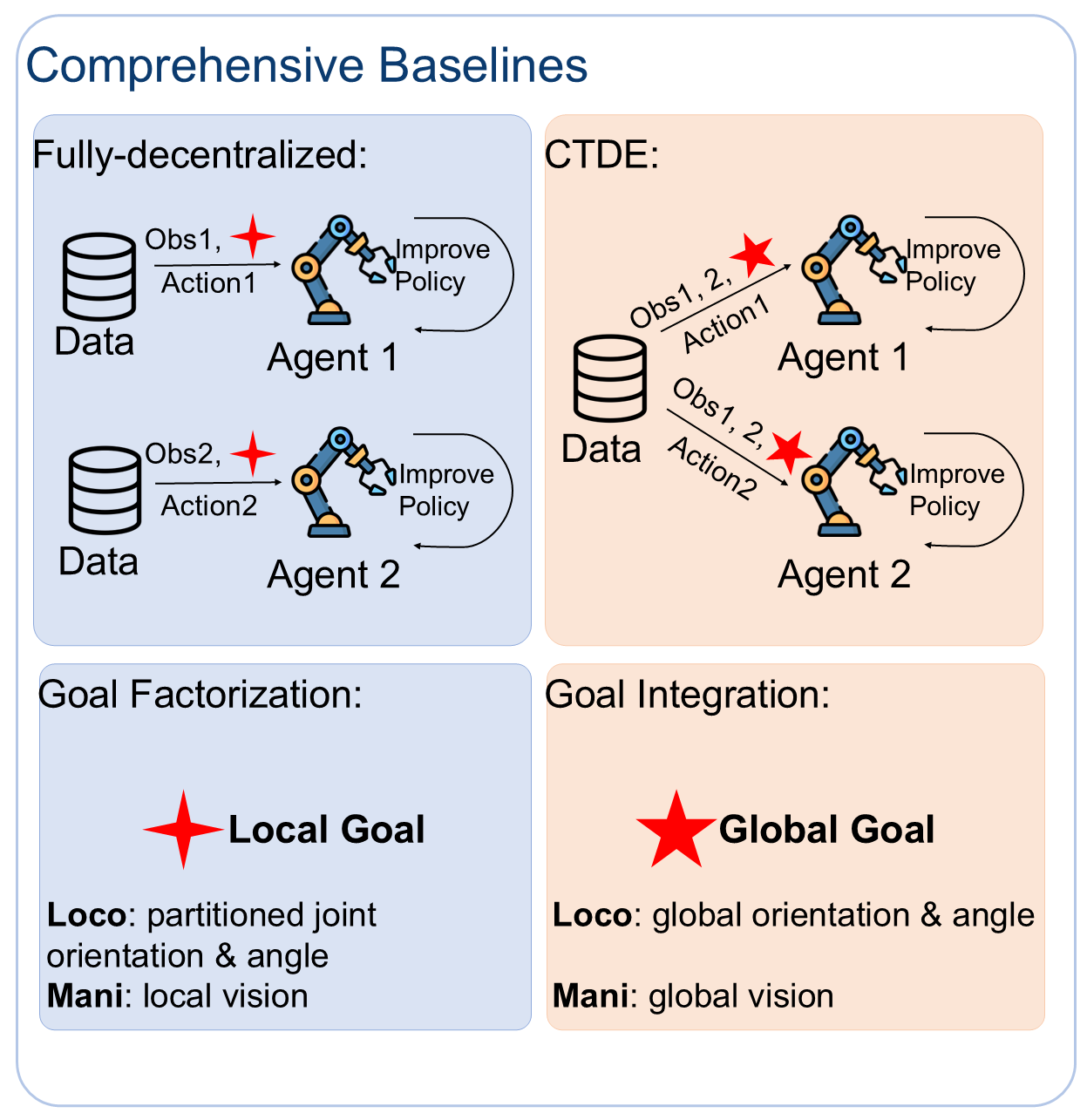
Multi-Agent Setting: We introduce a structured factorization of the robot body into different joints to make multiple agents within a single robot locomote cooperatively. The locomotion tasks involve three distinct multi-agent settings, including 2 agents × 4 joints, 2 agents × 4 joints (diagonal) and 4 agents × 2 joints.
The global goal corresponds to the complete joint states of the ant, whereas the local goals are derived from the structured factorization of the robot’s body, where each body part is assigned a goal based on its corresponding local joints for baseline training.
Multi-goal Evaluation: We utilize open-source datasets in OGBench. For complete assessment, we evaluate performance based on five predefined goals as outlined in OGBench.
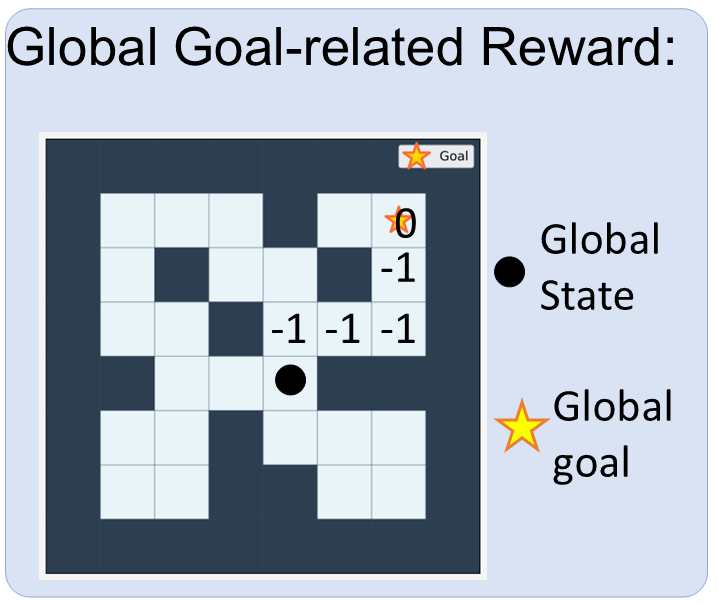
Goal-related Rewards Design: For joint-control tasks, we design a global goal-related reward to evaluate the collective efficacy of the unified control system. The reward is computed based on the global observation and the global goal, reflecting the overall performance of the entire robot (e.g., the locomotion system’s global orientation and position). The same scalar reward value is then broadcast to all agents, ensuring consistent optimization across all control modules. This design allows all agents in the unified control system to jointly pursue the same global objective while maintaining synchronized reward feedback.
Tasks and Demos: We extend the AntMaze and AntSoccer tasks in OGBench to a multi-agent setting. Example demos are shown as below, note that the first row of the videos corresponds to the input goal state.
Antmaze-Medium Demo
In this task, multiple agents jointly control different body parts to navigate through the maze and reach the goal.
AntMaze-Teleport Demo
"Teleport Maze" is a specially designed maze intended to test agents' ability to cope with environmental stochasticity. The maze features multiple random teleportation devices, where a black hole instantly transports the ant to a randomly selected white hole.
AntSoccer-Arena Demo
In the Ant-Soccer environment, a simulated ant is controlled by two or four cooperative agents, each manipulating specific joints to push a football and reach the goal. In Arena setting, agents operate in an open field without obstacles, learning stable walking gaits and precise force application to push the ball and reach the goal while maintaining balance and continuous contact.
AntSoccer-Medium Demo
The Maze setting introduces walls and narrow corridors between the start and goal positions, where agents must combine locomotion, ball control, and navigation planning to maneuver through the maze without trapping the ball, making it significantly more challenging than the open-field setting.
Cooperative Manipulation
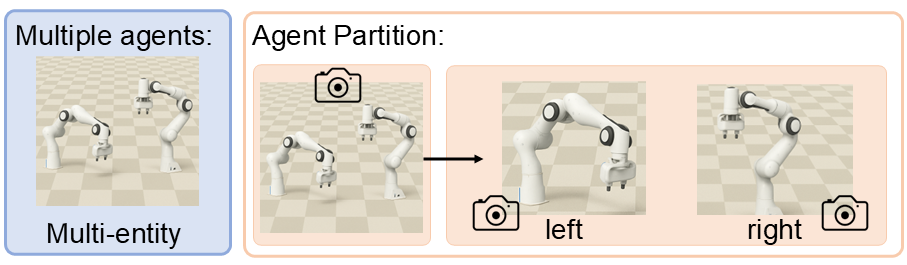
Multi-Agent Setting: To construct diverse multi-agent forms for a comprehensive evaluation of the baseline algorithms, we introduce multiple agent entities in the cooperative manipulation environment. For each robotic arm, its local visual observation is randomly sampled as the local goal, whereas the global goal is defined from the sampled global visual observation including both arms and the surrounding environment, serving as the goal input for training the goal-conditioned baselines.

Converted Standard RL datasets: We transform the open-source RoboFactory datasets into a format suitable for goal-conditioned offline MARL. Specifically, we reorganize the data into a standard Markov Decision Process (MDP) structure, where each sample includes a randomly sampled goal and a corresponding goal-conditioned reward. In contrast to the original datasets which is designed primarily for imitation learning frameworks such as Diffusion Policy (DP), our reformulation enables direct training of goal-conditioned offline MARL algorithms.










Multi-goal Evaluation: To avoid biased evaluation, each manipulation task is associated with 5 clearly defined sequential multiple goals to facilitate consistent comparison across algorithms. To ensure robustness, all evaluation metrics are averaged over 100 random seeds.

Goal-related Rewards Design: For multi-entity tasks, the reward function adopts a localized formulation that captures each entity’s individual contribution to the overall task performance. Each agent receives a goal-conditioned reward computed from its local observation and local goal, enabling each entity independently optimizes its goal-conditioned behavior while contributing to the cooperative task outcome.
Tasks and Demos: We adopt several two-agent cooperative manipulation tasks from RoboFactory for our experiments. Example demos are shown as below.
LiftBarrier Demo
The lift-barrier is a synchronous manipulation task that requires two robotic arms to simultaneously grasp both sides of a barrier and lift it to a target height, demanding precise temporal coordination between agents.
PlaceFood Demo
The place-food task involves asynchronous cooperation, where one arm must first open the pot lid before the other arm can place the food inside.
Results and Discussion
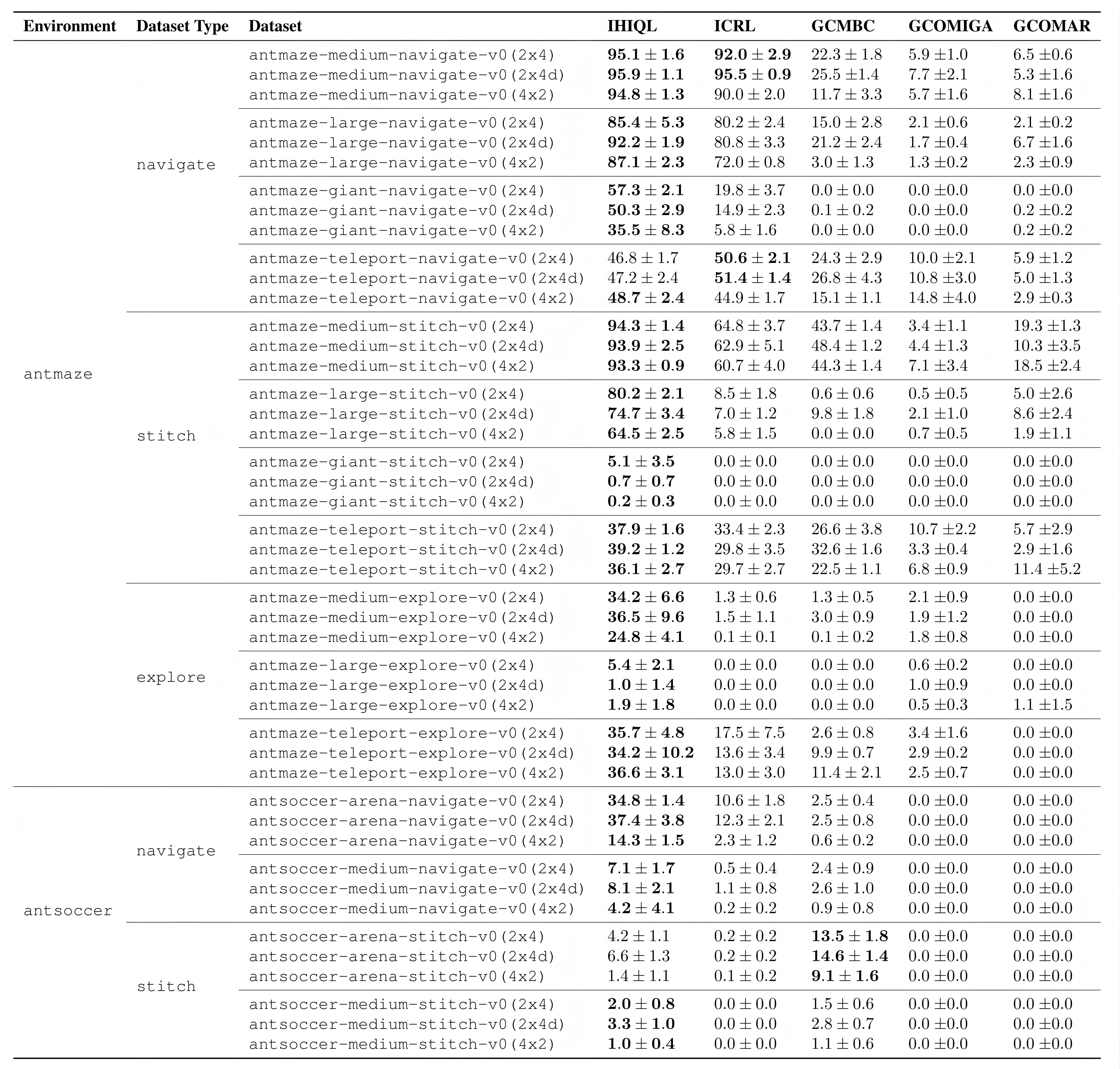
Benchmarking Results
Future Research
Designing Improved Algorithms under the CTDE Setting. We encourage future research to explore more efficient and coherent architectures for HIQL-CTDE, ones that preserve the coordination advantages of CTDE while mitigating its training instability. Such designs could potentially build upon the strong performance of IHIQL and further advance the understanding of goal representation learning in multi-agent settings.
Solving Sparse Reward Problem in Offline MARL. The analysis of OMIGA and OMAR reveals that existing offline MARL fail to overcome the challenge of sparse rewards. Since the dense rewards in real-world tasks (especially in multi-agent tasks) are difficult to design, we invite researchers to design more offline MARL or goal-conditioned offline MARL algorithms to address this issue.
BibTeX
@inproceedings{Wang2026MangoBench,
title={MangoBench: A Benchmark for Multi-Agent Goal-Conditioned Offline Reinforcement Learning},
author={Wang, Yi and Zhong, Ningze and Fu, Zhiheng and Wang, Longguang and Zhang, Ye and Guo, Yulan},
booktitle={IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
year={2026}
}